
# 一:前言

在redis中,当想要知道一个key的类型的时候,可以使用type命令。
> set a "123"
OK
> type a
string
## 如果这个key不存在的话,会返回none
> type abcd
none
2
3
4
5
6
7
8
redis数据结构内部编码,可以通过 object encoding 命令查询
> set hello 'sss'
OK
> object encoding hello
"embstr"
2
3
4
每种数据类型都提供了最少两种内部的编码格式,而且每个数据类型内部编码方式的选择对用户是完全透明的,Redis会根据数据量自适应地选择较优的内部编码格式。
这样设计好处
- 可以改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发出优秀的内部编码,无需改动外部数据结构和命令。
- 多种内部编码实现可以在不同场景下发挥各自的优势。例如 ziplist 比较节省内存,但是在列表元素比较多的情况下,性能会有所下降,这时候Redis会根据配置选项将列表类型的内部实现转换为 linkedlist。
# 二:字符串
字符串类型的内部编码有3种:
- int:8个字节的长整型
- embstr:小于等于39个字节的字符串
- raw:大于39个字节的字符串
Redis 会根据当前值的类型和长度决定使用哪种内部编码实现
# 2.1 整数类型
> set key 8653
OK
> object encoding key
"int"
## 它的范围是signed long 的最大最小值,超过了这个值,Redis 会报错
> set age 30
OK
> incr age
(integer) 31
> incrby age 5
(integer) 36
> incrby age -5
(integer) 31
> set codehole 9223372036854775807 # Long.Max
OK
> incr codehole
(error) ERR increment or decrement would overflow
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 2.2 短字符串
> set key "hello,world"
OK
> object encoding key
"embstr"
2
3
4
# 2.3 长字符串
> set str "Tranquil,unbeatable to the outside. -- yangming" #"凝聚于内,无敌于外。--王阳明"
OK
> object encoding str
"raw"
2
3
4
# 三:哈希
哈希类型的内部编码有两种:
ziplist(压缩列表):当哈希类型元素个数小于
hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,Redis 会使用 ziplist 作为哈希的内部实现,ziplist 使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比 hashtable 更加优秀hashtable(哈希表):当哈希类型无法满足 ziplist 的条件时,Redis 会使用 hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,而 hashtable 的读写时间复杂度为O(1)
# 3.1 ziplist
> hmset user:2 name kebi age 26
OK
> object encoding user:2
"ziplist"
2
3
4
# 3.2 hashtable
> hmset user:1 info "沐春风,惹一身红尘;望秋月,化半缕轻烟。顾盼间乾坤倒转,一霎时沧海桑田。方晓,弹指红颜老,刹那芳华逝。"
> object encoding user:1
"hashtable"
2
3
当一个哈希的编码由 ziplist 变为 hashtable 的时候,即使在替换掉所有值,它一直都会是 hashtable 类型。
# 四:列表
列表类型的内部编码有两种:
ziplist(压缩列表):当列表的元素个数小于
list-max-ziplist-entries配置 (默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时 (默认64字节),Redis会选用 ziplist 来作为列表的内部实现来减少内存的使用。linkedlist(链表):当列表类型无法满足 ziplist 的条件时,Redis会使用 linkedlist 作为列表的内部实现。
quicklist:3.2版本以后加入的结构,用于代替上述两种结构。
# 4.1 ziplist
> rpush list:2 a b c
(integer) 3
> object encoding list:2
"ziplist"
2
3
4
# 4.2 linkedlist
## 当元素个数超过512个,内部编码变为linkedlist
> lpush setkey 1 2 3 ... 513
OK
> object encoding listkey
"linkedlist"
## 当某个元素超过64个字节,内部编码也会变为linkedlist
> rpush list:1 a b "我不再说话,不再思索,但无尽的爱从灵魂中升起,我将远行,走得很远,如同一个吉普塞人,穿过大自然——幸福得如有一位女子同行。"
(integer) 6
> object encoding list:1
"linkedlist"
2
3
4
5
6
7
8
9
10
11
当一个列表的编码由 ziplist 变为 linkedlist 的时候,即使在替换掉所有值,它一直都会是 linkedlist类型。
# 4.3 quicklist
> rpush list:2 a b c
(integer) 3
> object encoding list:2
"quicklist"
> rpush list:1 a b "我不再说话,不再思索,但无尽的爱从灵魂中升起,我将远行,走得很远,如同一个吉普塞人,穿过大自然——幸福得如有一位女子同行。"
(integer) 6
> object encoding list:1
"quicklist"
2
3
4
5
6
7
8
# 五:集合
列表类型的内部编码有两种:
intset(整数集合):当集合中的元素都是整数且元素个数小于
set-max-intset-entries配置(默认512个)时,Redis 会选用 intset 来作为集合内部实现,从而减少内存的使用。hashtable(哈希表):当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable 作为集合的内部实现。
# 5.1 intset(整数集合)
> sadd setkey 2 3 4 5
(integer) 4
> object encoding setkey
"intset"
2
3
4
# 5.2 hashtable(哈希表)
## 当元素个数超过512个,内部编码变为hashtable
> sadd setkey2 1 2 3 4 5 6 7... 511 512 513
(integer) 513
> object encoding setkey2
"hashtable"
## 当某个元素不为整数时,内部编码也会变为hashtable
> sadd setkey3 a b c
(integer) 3
> object encoding setkey3
"hashtable"
2
3
4
5
6
7
8
9
10
11
# 六:有序集合
列表类型的内部编码有两种:
ziplist(压缩列表):当有序集合的元素个数小于
zset-max-ziplist-entries配置(默认128个)同时每个元素的值小于zset-max-ziplist-value配置(默认64个字节)时,Redis 会用 ziplist 来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。skiplist(跳跃表):当 ziplist 条件不满足时,有序集合会使用 skiplist 作为内部实现,因为此时 ziplist 的读写效率会下降。
# 6.1 ziplist(压缩列表)
> zadd zsetkey 50 a 60 b 30 c
(integer) 3
> object encoding zsetkey
"ziplist"
2
3
4
# 6.2 skiplist(跳跃表)
> zadd zsetkey 50 a 60 b 30 '闪烁的太阳已越过高傲的山峦,幽谷中的光点有若泡沫浮起。'
(integer) 1
> object encoding zsetkey
"skiplist"
2
3
4
zset 内部的排序功能是通过「跳跃列表」数据结构来实现的,它的结构非常特殊,也比较复杂。 因为 zset 要支持随机的插入和删除,所以它不好使用数组来表示。 我们需要这个链表按照 score 值进行排序。这意味着当有新元素需要插入时,要定位到特定位置的插入点,这样才可以继续保证链表是有序的。通常我们会通过二分查找来找到插入点,但是二分查找的对象必须是数组,只有数组才可以支持快速位置定位,链表做不到,那该怎么办? 跳跃列表就是类似于这种层级制,最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终就形成了金字塔结构。想想你老家在世界地图中的位置:亚洲->中国->安徽省->安庆市->枞阳县->汤沟镇->田间村->xxxx 号,也是这样一个类似的结构。
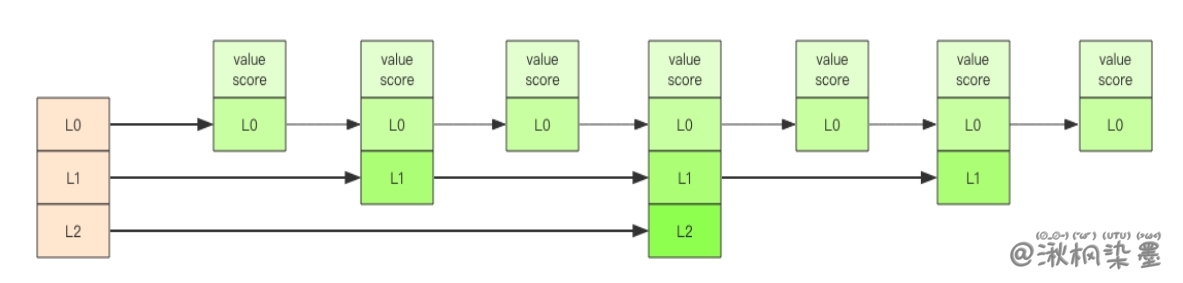
「跳跃列表」之所以「跳跃」,是因为内部的元素可能「身兼数职」,比如上图中间的这个元素,同时处于 L0、L1 和 L2 层,可以快速在不同层次之间进行「跳跃」。 定位插入点时,先在顶层进行定位,然后下潜到下一级定位,一直下潜到最底层找到合适的位置,将新元素插进去。你也许会问,那新插入的元素如何才有机会「身兼数职」呢? 跳跃列表采取一个随机策略来决定新元素可以兼职到第几层。 首先 L0 层肯定是 100% 了,L1 层只有 50% 的概率,L2 层只有 25% 的概率,L3 层只有 12.5% 的概率,一直随机到最顶层 L31 层。绝大多数元素都过不了几层,只有极少数元素可以深入到顶层。列表中的元素越多,能够深入的层次就越深,能进入到顶层的概率就会越大。 这还挺公平的,能不能进入中央不是靠拼爹,而是看运气。
# 七:参考文献
- 《Redis深度历险:核心原理和应用实践 - 钱文品》
- 《Redis 开发与运维 - 付磊、张益军》
- Redis五大数据类型内部编码剖析 (opens new window)
- 快速搞懂Redis五种基本数据类型的内部编码 (opens new window)
- redis数据结构及内部编码-string数据结构 (opens new window)
- 官方文档 (opens new window)